
Performance engineering
Within systems engineering, performance engineering encompasses the set of roles, skills, activities, practices, tools, and deliverables applied at every phase of the Systems Development Lifecycle which ensures that a solution will be designed, implemented, and operationally supported to meet the non-functional requirements defined for the solution. It may be alternatively referred to as software performance engineering within software engineering; however since performance engineering encompasses more than just the software, the term performance engineering is preferable. Adherence to the non-functional requirements is validated by monitoring the production systems. This is part of IT service management (see also ITIL).
Performance engineering has become a separate discipline at a number of large corporations, and may be affiliated with the enterprise architecture group. It is pervasive, involving people from multiple organizational units; but predominantly within the information technology organization.
Performance Engineering Objective
- Increase business revenue by ensuring the system can process transactions within the requisite timeframe
- Eliminate system failure requiring scrapping and writing off the system development effort due to performance objective failure
- Eliminate late system deployment due to performance issues
- Eliminate avoidable system rework due to performance issues
- Eliminate avoidable system tuning efforts
- Avoid additional and unnecessary hardware acquisition costs
- Reduce increased software maintenance costs due to performance problems in production
- Reduce increased software maintenance costs due to software impacted by ad hoc performance fixes
- Reduce additional operational overhead for handling system issues due to performance problems
Performance Engineering Approach
Because this discipline is applied within multiple methodologies, the following activities will occur within differently specified phases. However if the phases of the rational unified process (RUP) are used as a framework, then the activities will occur as follows:
Inception
During this first conceptual phase of a program or project, critical business processes are identified. Typically they are classified as critical based upon revenue value, cost savings, or other assigned business value. This classification is done by the business unit, not the IT organization.
High level risks that may impact system performance are identified and described at this time. An example might be known performance risks for a particular vendor system.
Finally performance activities, roles, and deliverables are identified for the Elaboration phase. Activities and resource loading are incorporated into the Elaboration phase project plans.
Elaboration
During this defining phase, the critical business processes are decomposed to critical use cases. Such use cases will be decomposed further, as needed, to single page (screen) transitions. These are the use cases that will be subjected to script driven performance testing.
The type of requirements that relate to Performance Engineering are the non-functional requirements, or NFR. While a functional requirement relates to what business operations are to be performed, a performance related non-functional requirement will relate to how fast that business operation performs under defined circumstances.
The concept of "defined circumstances" is vital. This will be illustrated by example:
- Invalid – the system should respond to user input within 10 seconds.
- Valid – for use case ABC the system will respond to a valid user entry within 5 seconds for a median load of 250 active users and 2000 logged in users 95% of the time; or within 10 seconds for a peak load of 500 active users and 4000 logged in users 90% of the time.
Note the critical differences between the two specifications. The first example provides no conditions. The second clearly identifies the conditions under which the system is to perform. The second example may have a service level agreement, the first should not. The capacity planners and architects can actually design and build a system to meet the criteria for the valid nonfunctional requirement – but not for the invalid one. Testers may build a reliable performance test for the second example, but not for the invalid example.
Each critical use case must have an associated NFR. If, for a given use case, no existing NFR is applicable, a new NFR specific to that use case must be created.
Non functional requirements are not limited to use cases. The overall system volumetrics must be specified. These will describe the overall system load over a specified time period, defining how many of each type of business transaction will be executed per unit of time. Commonly volumetrics describe a typical business day, and then are broken down for each hour. This will describe how system load will vary over the course of the day. For example: 1200 of transaction A, 300 of transaction B, 3300 of transaction C, etc. for a given business day; then in hour 1 so many executions of A, B, C etc., in hour 2 so many transaction exections, and so on. The information is often formatted in a tabular form for clarity. If different user classes are executing the transactions, this information will also be incorporated in the NFR documentation. Finally, the transactions may be classified as to general type, normally being user interaction, report generation, and batch processing.
The system volumetrics documented in the NFR documentation will be used as inputs for both load testing and stress testing of the system during the performance test.
At this point it is suggested that performance modeling be performed using the use case information as input. This may be done using a performance lab, and using prototypes and mockups of the “to be” system; or a vendor provided modeling tool may be used; or even merely a spreadsheet workbook, where each use case is modeled in a single sheet, and a summary sheet is used to provide high level information for all of the use cases.
It is recommended that Unified Modeling Language sequence diagrams be generated at the physical tier level for each use case. The physical tiers are represented by the vertical object columns, and the message communication between the tiers by the horizontal arrows. Timing information should be associated with each horizontal arrow; this should correlate with the performance model.
Some performance engineering activities related to performance testing should be executed in this phase. They include validating a performance test strategy, developing a performance test plan, determining the sizing of test data sets, developing a performance test data plan, and identifying performance test scenarios.
For any system of significant impact, a monitoring plan and a monitoring design are developed in this phase. Performance engineering applies a subset of activities related to performance monitoring, both for the performance test environment as well as for the production environment.
The risk document generated in the previous phase is revisited here. A risk mitigation plan is determined for each identified performance risk; and time, cost, and responsibility is determined and documented.
Finally performance activities, roles, and deliverables are identified for the Construction phase. Activities and resource loading are incorporated into the Construction phase project plans. These will be elaborated for each iteration.
Construction
Early in this phase a number of performance tool related activities are required. These include:
- Identify key development team members as subject matter experts for the selected tools
- Specify a profiling tool for the development/component unit test environment
- Specify an automated unit (component) performance test tool for the development/component unit test environment; this is used when no GUI yet exists to drive the components under development
- Specify an automated tool for driving server-side unit (components) for the development/component unit test environment
- Specify an automated multi-user capable script driven end to end tool for the development/ component unit test environment; this is used to execute screen driven use cases
- Identify a database test data load tool for the development/component unit test environment; this is required to ensure that the database optimizer chooses correct execution paths and to enable reinitializing and reloading the database as needed
- Deploy the performance tools for the development team
- Presentations and training must be given to development team members on the selected tools
A member of the performance engineering practice and the development technical team leads should work together to identify performance-oriented best practices for the development team. Ideally the development organization should already have a body of best practices, but often these do not include or emphasize those best practices that impact system performance.
The concept of application instrumentation should be introduced here with the participation of the IT Monitoring organization. Several vendor monitoring systems have performance capabilities, these normally operate at the operating system, network, and server levels; e.g. CPU utilization, memory utilization, disk I/O, and for J2EE servers the JVM performance including garbage collection.
But this type of monitoring does not permit the tracking of use case level performance. To reach this level of monitoring capability may require that the application itself be instrumented. Alternatively, a monitoring toolset that works at the switch level may be used. (Examples might be TeaLeaf's Cx technology, Hewlett-Packard's RUM, NetQoS's SuperAgent, or Compuware's agentless ClientVantage.) The monitoring group should have specified the requirements in a previous phase, and should work with the development team to ensure that use case level monitoring is built in.
The group responsible for infrastructural performance tuning should have an established "base model" checklist to tune the operating systems, network, servers (application, web, database, load balancer, etc.), and any message queueing software. Then as the performance test team starts to gather data, they should commence tuning the environment more specifically for the system to be deployed. This requires the active support of subject matter experts, for example, database tuning normally requires a DBA who has special skills in that area.
The performance test team normally does not execute performance tests in the development environment, but rather in a specialized pre-deployment environment that is configured to be as close as possible to the planned production environment. This team will execute performance testing against test cases, validating that the critical use cases conform to the specified non-functional requirements. The team will execute load testing against a normally expected (median) load as well as a peak load. They will often run stress tests that will identify the system bottlenecks. The data gathered, and the analyses, will be fed back to the group that does performance tuning. Where necessary, the system will be tuned to bring nonconforming tests into conformance with the non-functional requirements.
If performance engineering has been properly applied at each iteration and phase of the project to this point, hopefully this will be sufficient to enable the system to receive performance certification. However, if for some reason (perhaps proper performance engineering working practices were not applied) there are tests that cannot be tuned into compliance, then it will be necessary to return portions of the system to development for refactoring. In some cases the problem can be resolved with additional hardware, but adding more hardware leads quickly to diminishing returns.
For example: suppose we can improve 70% of a module by parallelizing it, and run on 4 CPUs instead of 1 CPU. If α is the fraction of a calculation that is sequential, and (1-α) is the fraction that can be parallelized, then the maximum speedup that can be achieved by using P processors is given according to Amdahl's Law: 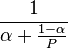
In this example we would get: 1/(.3+(1-.3)/4)=2.105. So for quadrupling the processing power we only doubled the performance (from 1 to 2.105). And we are now well on the way to diminishing returns. If we go on to double the computing power again from 4 to 8 processors we get 1/(.3+(1-.3)/8)=2.581. So now by doubling the processing power again we only got a performance improvement of about one fifth (from 2.105 to 2.581).
Throwing more CPUs at the problem helps a little, but since adding more CPUs causes more memory utilization and more I/O traffic we may not even get that increase. Maybe you crash the JVM. Or cause database "thrashing". Etcetera. So, more money spent on hardware for diminishing returns or possibly even worse performance than you started with.
Transition
During this final phase the system is deployed to the production environment. A number of preparatory steps are required. These include:
- Configuring the operating systems, network, servers (application, web, database, load balancer, etc.), and any message queueing software according to the base checklists and the optimizations identified in the performance test environment
- Ensuring all performance monitoring software is deployed and configured
- Running Statistics on the database after the production data load is completed
Once the new system is deployed, ongoing operations pick up performance activities, including:
- Validating that weekly and monthly performance reports indicate that critical use cases perform within the specified non functional requirement criteria
- Where use cases are falling outside of NFR criteria, submit defects
- Identify projected trends from monthly and quarterly reports, and on a quarterly basis, execute capacity planning management activities
Service Management
In the operational domain (post production deployment) performance engineering focuses primarily within three areas: service level management, capacity management, and problem management.
Service Level Management
In the service level management area, performance engineering is concerned with service level agreements and the associated systems monitoring that serves to validate service level compliance, detect problems, and identify trends. For example, when real user monitoring is deployed it is possible to ensure that user transactions are being executed in conformance with specified non-functional requirements. Transaction response time is logged in a database such that queries and reports can be run against the data. This permits trend analysis that can be useful for capacity management. When user transactions fall out of band, the events should generate alerts so that attention may be applied to the situation.
Capacity Management
For capacity management, performance engineering focuses on ensuring that the systems will remain within performance compliance. This means executing trend analysis on historical monitoring generated data, such that the future time of non compliance is predictable. For example, if a system is showing a trend of slowing transaction processing (which might be due to growing data set sizes, or increasing numbers of concurrent users, or other factors) then at some point the system will no longer meet the criteria specified within the service level agreements. Capacity management is charged with ensuring that additional capacity is added in advance of that point (additional CPUs, more memory, new database indexing, etcetera) so that the trend lines are reset and the system will remain within the specified performance range.
Problem Management
Within the problem management domain, the performance engineering practices are focused on resolving the root cause of performance related problems. These typically involve system tuning, changing operating system or device parameters, or even refactoring the application software to resolve poor performance due to poor design or bad coding practices.
Monitoring
To ensure that there is proper feedback validating that the system meets the NFR specified performance metrics, any major system needs a monitoring subsystem. The planning, design, installation, configuration, and control of the monitoring subsystem is specified by an appropriately defined Monitoring Process. The benefits are as follows:
- It is possible to establish service level agreements at the use case level.
- It is possible to turn on and turn off monitoring at periodic points or to support problem resolution.
- It enables the generation of regular reports.
- It enables the ability to track trends over time – such as the impact of increasing user loads and growing data sets on use case level performance.
The trend analysis component of this cannot be undervalued. This functionality, properly implemented, will enable predicting when a given application undergoing gradually increasing user loads and growing data sets will exceed the specified non functional performance requirements for a given use case. This permits proper management budgeting, acquisition of, and deployment of the required resources to keep the system running within the parameters of the non functional performance requirements.
1 comment:
This is very good information.i think it's useful advice. really nice blog. keep it up!!!
performance engineering
Post a Comment